¿Necesitas saber si el archivo llms.txt funciona?
En los últimos meses ha comenzado a popularizarse el archivo llms.txt como un nuevo método para comunicarse con los agentes de inteligencia artificial y sus bots que rastrean la web. Inspirado en la filosofía de robots.txt, este archivo pretende ofrecer instrucciones específicas para sistemas de IA: qué contenidos pueden usar para entrenamiento, cuáles pueden resumir, indexar o citar, y bajo qué condiciones.
La idea es sencilla: si los modelos de lenguaje están consumiendo la web de forma masiva, debería existir una forma estandarizada y transparente de indicarles cómo queremos que utilicen nuestros contenidos. Sin embargo, la práctica dista bastante de la teoría. Hay webs complicadas que pueden necesitar y sacar provecho de este tipo de comunicación pero para webs pequeñas de pymes lo más seguro es que coincida todo con las mismas urls del sitemap.
¿Qué es exactamente llms.txt?
El archivo llms.txt es una propuesta no oficial creada por unos pocos SEO que han creado una página donde lo explican pero cada vez más citada en comunidades técnicas y de SEO avanzado. Su objetivo es servir como punto de referencia para:
- Contenidos que pueden ser usados para entrenamiento de modelos.
- Secciones recomendadas para resúmenes o respuestas directas.
- Información de contexto “canónica” del sitio (descripciones, avisos legales, licencias).
- Exclusiones explícitas de uso por parte de sistemas de IA.
A diferencia de robots.txt, que se dirige a crawlers tradicionales, llms.txt está pensado para modelos generativos, no solo para indexación sino para reutilización semántica del contenido.
El problema del archivo llms.txt es su adopción mínima y su poco uso.
El principal reto de llms.txt no es técnico, sino de adopción. No existe una obligación real para que los bots de IA lo respeten, ni siquiera para que lo consulten. A día de hoy:
- No hay un estándar formal respaldado por un organismo reconocido. Solo desde esa página. Eso si, existen muchos validadores.
- Muchos proveedores de IA no documentan públicamente si lo usan o cómo. Ninguno ha dicho que lo usa.
- Algunos bots se identifican de forma ambigua o directamente no se identifican como bots de IA.
Esto provoca que, aunque los administradores de sitios web implementen llms.txt de buena fe, no tengan garantías de que sus instrucciones sean leídas o respetadas. De hecho, gran parte de las implementaciones realizadas se hacen para contentar al cliente en contra del pensamiento de la mayoría de técnicos de marketing.
Identificación de bots que no se quieren identificar
Otro aspecto preocupante es la identificación de los agentes que acceden a estos archivos. Mientras que los crawlers clásicos suelen usar user agents claros y documentados, los bots asociados a sistemas de IA a menudo:
- Utilizan user agents genéricos de navegador.
- Simulan dispositivos móviles antiguos.
- No incluyen referencias claras a la empresa o producto que los opera.
Esto dificulta enormemente la auditoría, la trazabilidad y la confianza en el ecosistema.
¿Tiene sentido usar llms.txt hoy?
A pesar de sus limitaciones actuales, llms.txt tiene valor como señal declarativa:
- Deja constancia explícita de la voluntad del webmaster de mantener una política de uso para los bots de IA.
- Facilita un marco futuro si el estándar se consolida.
- Puede servir como evidencia de postura en conflictos legales o de uso indebido.
No obstante, confiar en él como mecanismo de control efectivo hoy en día es, como mínimo, optimista. Si un cliente me pregunta le diría que no pierda tiempo en crear ese archivo hasta que alguna de las empresas potentes de Inteligencia artificial como OpenAI o Perplexity digan que lo están usando.
La necesidad de pasar del “archivo” a la observación estadística real
Ante esta falta de transparencia, limitarse a generar un llms.txt estático aporta poco valor si no se acompaña de visibilidad real sobre quién lo está leyendo. En el contexto SEO actual, donde cada señal cuenta, saber qué actores acceden a este archivo es casi tan importante como su contenido.
Precisamente por esta razón he desarrollado un plugin con relevancia en el mundo SEO que va un paso más allá de la simple creación del archivo con las entradas del blog.
Un plugin SEO que genera llms.txt y audita las IP que leen el archivo
El plugin no solo genera automáticamente el archivo llms.txt a partir de las entradas del blog, estructurando la información de forma coherente y útil para modelos de lenguaje, sino que añade una capa crítica de observabilidad:
- Registra quién accede al archivo
llms.txt. - Muestra datos clave como:
- Dirección IP
- User agent
- Fecha y frecuencia de acceso
- Clasifica las visitas indicando si se trata de:
- Un bot identificado
- Una visita no identificada o sospechosa. En este caso hablo de humanos hasta que se demuestre lo contrario.
De este modo, el llms.txt deja de ser un simple manifiesto declarativo y se convierte en una fuente de datos real, alineada con una mentalidad SEO basada en logs, evidencia y trazabilidad.
URL del plugin para descargarlo: https://wordpress.org/plugins/cf-llms-stats-tracker/ CF LLMS STATS TRACKER
Colofón: datos reales de acceso a llms.txt
En mi caso concreto, dispongo de estadísticas de acceso al archivo llms.txt durante los últimos meses sobre varios dominios. Los datos son reveladores:
- Solo un bot conocido, identificado claramente como perteneciente a la empresa dataprovider.com, ha accedido de forma coherente y reconocible.
- Además, se ha registrado un acceso desde infraestructura de Google, pero sin identificarse como bot de Google.
Este segundo acceso utiliza un user agent poco habitual:
Mozilla/5.0 (Linux; Android 8.1.0; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Mobile Safari/537.36 PTST/251202.154650
Se trata de la emulación de un móvil antiguo (Moto G4), incluyendo el identificador PTST, habitualmente asociado a herramientas internas de page testing.
El acceso proviene de la IP IPv6:
2600:1900:4090:1d:0:2fc::
Este tipo de comportamiento refuerza la idea de que, aunque algunos grandes actores sí consultan llms.txt, lo hacen de manera opaca, sin una identificación clara ni explícita como bots de IA.
En resumen, llms.txt apunta en la dirección correcta, pero hoy por hoy sigue siendo más una declaración de intenciones que una herramienta efectiva de control. El plugin que he programado te ayuda a saber si realmente vale la pena dedicarle tiempo a la creación de un archivo llms.txt manual con criterios SEO/GEO o por contra te vale con el archivo generado automáticamente por este plugin o por cualquier otro.
Otras visitas sin identificarse como bots (datos de todo 2025):
35.207.52.32
34.1.31.112
35.215.77.83
35.212.150.165
34.0.152.86
35.211.76.12
35.212.128.251
Todas estas IP son de Google Cloud. Tienen pinta de tratarse de bots de alguna empresa que ha contratado los servicios de Google en la nube.
Bots desde IP de OVH:
49.56.150.36
149.56.160.164
149.56.150.141
149.56.160.171
¿Hay bots de IA visitando los sitemap?
La respuesta es afirmativa. Los datos de este blog para el mes de diciembre indican que al menos el bot de Claude visita regularmente los archivos tradicionales de sitemap y no visita el archivo llms.txt. A día de hoy es mucho más relevante cuidar tus archivos de sitemap que dedicar tiempo al archivo llms.txt.
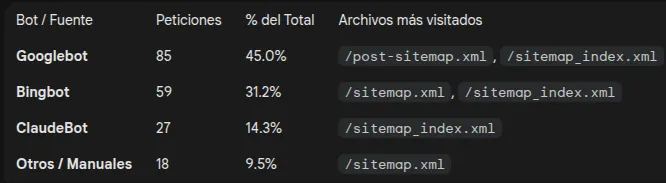
Lo he probado estos días y la verdad es que me ha sorprendido para bien. Es sencillo de usar, no añade ruido innecesario y se nota que está pensado para un uso real con LLMs, no solo “por cumplir”. Por ahora solo sale mi IP. Lo miraré semanalmente a ver si cae alguno de los grandes.