Comparativa de Modelos de IA Locales
En las últimas semanas he estado haciendo pruebas con distintos modelos de inteligencia artificial que tengo instalados en mi propio ordenador. Mi objetivo era comprobar cuál de ellos ofrecía mejores tiempos de respuesta al realizar una serie de tareas complejas. La experiencia no solo me permitió conocer mejor sus capacidades, sino también reflexionar sobre el potencial de tener estas herramientas funcionando de forma completamente local, sin depender de la nube ni de servicios externos.
Los Modelos Probados
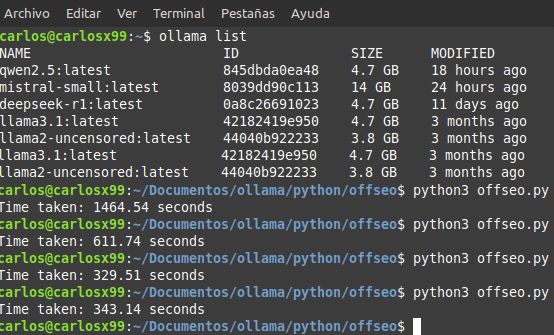
En total, ejecuté la prueba con cinco modelos distintos. Todos ellos funcionan de forma local en mi equipo, el cual cuenta con una tarjeta gráfica de apenas 2GB, lo que ya nos da una idea de las limitaciones a nivel de hardware. Aun así, los resultados fueron bastante interesantes.
Los modelos utilizados fueron:
LLaMA 3.1
Qwen 2.5
DeepSeek
Mistral-Small (ya desinstalado tras la prueba)
LLaMA 2 Uncensored (para pruebas más flexibles, no incluida en los benchmarks de tiempo)
La Prueba: Tareas Reales y Medibles
La comparativa consistió en asignar a cada modelo una batería de cinco tareas idénticas. Las instrucciones eran del tipo:
«Haz un texto resumen de la página xxxx en 600 palabras. Analiza tanto la estructura como el contenido. Especula cuál es el tipo de público objetivo. ¿Cómo se podría mejorar el contenido? ¿Y la estructura?»
Cada modelo debía repetir este proceso para cinco URLs distintas. Es decir, 25 respuestas en total, cada una implicando comprensión, análisis y redacción coherente y profunda.
El script, programado en Python, generaba un archivo .csv con las respuestas y medía el tiempo que cada modelo tardaba en completarlas.
Resultados y Rendimiento
Los resultados fueron reveladores. LLaMA 3.1 y Qwen 2.5 fueron los más eficientes, completando todas las tareas en poco más de 300 segundos. DeepSeek necesitó algo más del doble, superando los 600 segundos. Por último, Mistral-Small —ya desinstalado por motivos de rendimiento— se demoró casi 1500 segundos.
Teniendo en cuenta que el equipo no es especialmente potente, obtener una respuesta por minuto de media ya es bastante aceptable. La optimización del modelo y su capacidad de adaptación a recursos limitados es claramente un factor determinante.
Ventajas de la IA Local
Más allá de los tiempos, lo que realmente me sorprende de tener modelos de IA funcionando de forma privada es la flexibilidad y el control total que se obtiene. No hay censura, límites de consultas o dependencias externas. Por ejemplo, tengo instalada una versión sin restricciones de LLaMA 2 (llamada uncensored) a la que se le puede preguntar absolutamente cualquier cosa, sin filtros ni bloqueos.
Esto abre un abanico de posibilidades para usuarios avanzados y desarrolladores. Desde traducir automáticamente el contenido completo de una web hasta generar descripciones extensas para cada producto de una tienda online, o incluso expandir el contenido de un dominio entero con textos útiles, únicos y relevantes.
Automatización y Desarrollo Web
Estas herramientas son una auténtica joya para quienes se dedican al desarrollo de sitios web automatizados. Poder generar contenido original y específico para distintas secciones de una página, sin tener que pasar por APIs externas o pagar suscripciones mensuales, representa un salto cualitativo importante. Además, al estar los modelos en local, el proceso es completamente privado.
Estamos en un momento apasionante para la inteligencia artificial a nivel personal. Lo que antes era dominio exclusivo de grandes centros de datos, hoy puede ejecutarse en un ordenador modesto desde casa. Sí, los tiempos de respuesta no son instantáneos, pero las ventajas en privacidad, control y personalización hacen que valga la pena y con una buena tarjeta gráfica los tiempos disminuyen drásticamente.
Este tipo de comparativas caseras son solo una muestra del enorme potencial de la IA local. Y lo mejor es que esto no ha hecho más que empezar.
Comentarios recientes